






Picture created by Creator
Introduction
An essential step in producing predictive fashions is deciding on the right machine studying algorithm to make use of, a selection which may have a seemingly out-sized impact on mannequin efficiency and effectivity. This choice may even decide the success of essentially the most fundamental of predictive duties: whether or not a mannequin is ready to sufficiently be taught from coaching knowledge and generalize to new units of information. That is particularly essential for knowledge science practitioners and college students, who face an awesome variety of potential selections as to which algorithm to run with. The aim of this text is to assist demystify the method of choosing the proper machine studying algorithm, concentrating on “conventional” algorithms and providing some pointers for selecting the perfect one in your utility.
The Significance of Algorithm Choice
The selection of a finest, appropriate, and even ample algorithm can dramatically enhance a mannequin’s means to foretell precisely. The unsuitable selection of algorithm, as you may be capable of guess, can result in suboptimal mannequin efficiency, maybe not even reaching the edge of being helpful. This leads to a considerable potential benefit: deciding on the “proper” algorithm which matches the statistics of the info and drawback will enable a mannequin to be taught effectively and supply outputs extra precisely, probably in much less time. Conversely, selecting the wrong algorithm can have a variety of damaging penalties: coaching instances is likely to be longer; coaching is likely to be extra computationally costly; and, worst of all, the mannequin may very well be much less dependable. This might imply a much less correct mannequin, poor outcomes when given new knowledge, or no precise insights into what the info can let you know. Doing poorly on all or any of those metrics can in the end be a waste of sources and might restrict the success of your entire venture.
tl;dr Accurately selecting the best algorithm for the duty instantly influences machine studying mannequin effectivity and accuracy.
Algorithm Choice Concerns
Choosing the proper machine studying algorithm for a process entails quite a lot of elements, every of which is ready to have a big affect on the eventual determination. What follows are a number of aspects to remember through the decision-making course of.
Dataset Traits
The traits of the dataset are of the utmost significance to algorithm choice. Elements akin to the dimensions of the dataset, the kind of knowledge parts contained, whether or not the info is structured or unstructured, are all top-level elements. Think about using an algorithm for structured knowledge to an unstructured knowledge drawback. You in all probability will not get very far! Giant datasets would want scalable algorithms, whereas smaller ones might do advantageous with less complicated fashions. And remember the standard of the info — is it clear, or noisy, or perhaps incomplete — owing to the truth that completely different algorithms have completely different capabilities and robustness on the subject of lacking knowledge and noise.
Drawback Sort
The kind of drawback you are attempting to unravel, whether or not classification, regression, clustering, or one thing else, clearly impacts the number of an algorithm. There are explicit algorithms which might be finest fitted to every class of drawback, and there are lots of algorithms that merely don’t work for different drawback sorts in any way. In case you have been engaged on a classification drawback, for instance, you is likely to be selecting between logistic regression and help vector machines, whereas a clustering drawback may lead you to utilizing k-means. You probably wouldn’t begin with a choice tree classification algorithm in an try to unravel a regression drawback.
Efficiency Metrics
What are the methods you plan to seize for measuring your mannequin’s efficiency? In case you are set on explicit metrics — as an illustration, precision or recall in your classification drawback, or imply squared error in your regression drawback — you could make sure that the chosen algorithm can accommodate. And do not overlook extra non-traditional metrics akin to coaching time and mannequin interpretability. Although some fashions may prepare extra shortly, they might achieve this at the price of accuracy or interpretability.
Useful resource Availability
Lastly, the sources you might have obtainable at your disposal might vastly affect your algorithm determination. For instance, deep studying fashions may require a great deal of computational energy (e.g., GPUs) and reminiscence, making them lower than best in some resource-constrained environments. Figuring out what sources can be found to you possibly can assist making a decision that may assist make tradeoffs between what you want, what you might have, and getting the job finished.
By thoughtfully contemplating these elements, a sensible choice of algorithm could be made which not solely performs effectively, however aligns effectively with the targets and restrictions of the venture.
Newbie’s Information to Algorithm Choice
Beneath is a flowchart that can be utilized as a sensible software in guiding the number of a machine studying algorithm, detailing the steps that should be taken from the issue definition stage by way of to the finished deployment of a mannequin. By adhering to this structured sequence of selection factors and concerns, a consumer can efficiently consider elements that may play an element in deciding on the right algorithm for his or her wants.
Choice Factors to Take into account
The flowchart identifies a lot of particular determination factors, a lot of which has been coated above:
- Decide Knowledge Sort: Understanding whether or not knowledge is in structured or unstructured type can assist direct the place to begin for selecting an algorithm, as can figuring out the person knowledge component sorts (integer, Boolean, textual content, floating level decimal, and so on.)
- Knowledge Dimension: The scale of a dataset performs a big position in deciding whether or not a extra easy or extra complicated mannequin is related, relying on elements like knowledge measurement, computational effectivity, and coaching time
- Sort of Drawback: Exactly what sort of machine studying drawback is being tackled — classification, regression, clustering, or different — will dictate what set of algorithms is likely to be related for consideration, with every group providing an algorithm or algorithms that may be suited to the alternatives made about the issue so far
- Refinement and Analysis: The mannequin which ends type the chosen algorithm will typically proceed from selection, by way of to parameter finetuning, after which end in analysis, with every step being required to find out algorithm effectiveness, and which, at any level, might result in the choice to pick one other algorithm
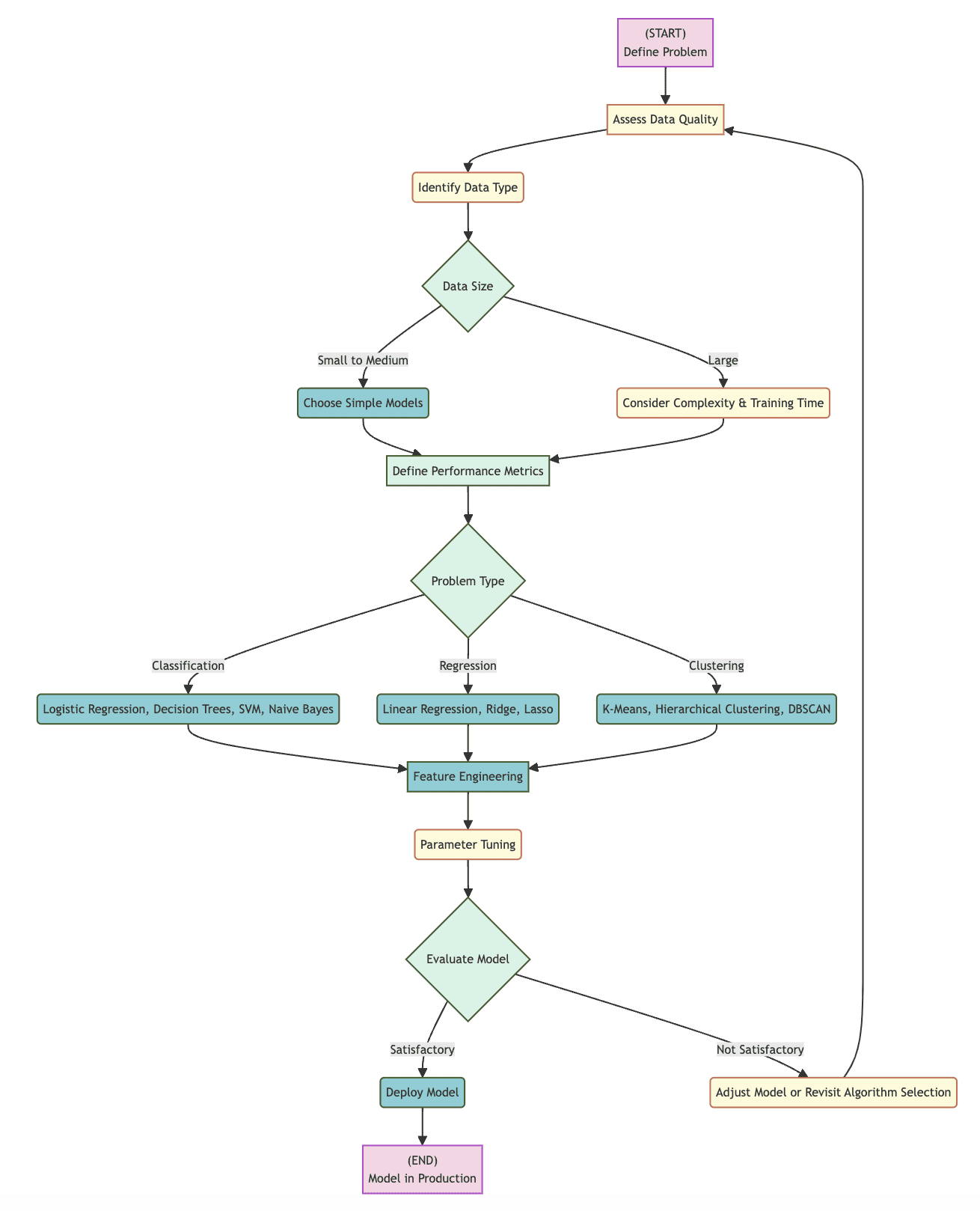
Flowchart visualization created by Creator (click on to enlarge)
Taking it Step by Step
From begin to end, the above flowchart outlines an evolution from drawback definition, by way of knowledge kind identification, knowledge measurement evaluation, drawback categorization, to mannequin selection, refinement, and subsequent analysis. If the analysis signifies that the mannequin is passable, deployment may proceed; if not, an alteration to the mannequin or a brand new try with a unique algorithm could also be vital. By rendering the algorithm choice steps extra easy, it’s extra probably that the best algorithm can be chosen for a given set of information and venture specs.
Step 1: Outline the Drawback and Assess Knowledge Traits
The foundations of choosing an algorithm reside within the exact definition of your drawback: what you wish to mannequin and which challenges you’re attempting to beat. Concurrently, assess the properties of your knowledge, akin to the info’s kind (structured/unstructured), amount, high quality (absence of noise and lacking values), and selection. These collectively have a robust affect on each the extent of complexity of the fashions you’ll be capable of apply and the sorts of fashions you could make use of.
Step 2: Select Applicable Algorithm Primarily based on Knowledge and Drawback Sort
The next step, as soon as your drawback and knowledge traits are laid naked beforehand, is to pick an algorithm or group of algorithms best suited in your knowledge and drawback sorts. For instance, algorithms akin to Logistic Regression, Choice Timber, and SVM may show helpful for binary classification of structured knowledge. Regression might point out using Linear Regression or ensemble strategies. Cluster evaluation of unstructured knowledge might warrant using Ok-Means, DBSCAN, or different algorithms of the kind. The algorithm you choose should be capable of sort out your knowledge successfully, whereas satisfying the necessities of your venture.
Step 3: Take into account Mannequin Efficiency Necessities
The efficiency calls for of differing tasks require completely different methods. This spherical entails the identification of the efficiency metrics most essential to your enterprise: accuracy, precision, recall, execution pace, interpretability, and others. For example, in vocations when understanding the mannequin’s inside workings is essential, akin to finance or medication, interpretability turns into a vital level. This knowledge on what traits are essential to your venture should in flip be broadsided with the identified strengths of various algorithms to make sure they’re met. Finally, this alignment ensures that the wants of each knowledge and enterprise are met.
Step 4: Put Collectively a Baseline Mannequin
As an alternative of placing out for the bleeding fringe of algorithmic complexity, start your modeling with an easy preliminary mannequin. It must be simple to put in and quick to run, offered the estimation of efficiency of extra complicated fashions. This step is important for establishing an early-model estimate of potential efficiency, and should level out large-scale points with the preparation of information, or naïve assumptions that have been made on the outset.
Step 5: Refine and Iterate Primarily based on Mannequin Analysis
As soon as the baseline has been reached, refine your mannequin based mostly on efficiency standards. This entails tweaking mannequin’s hyperparameters and have engineering, or contemplating a unique baseline if the earlier mannequin doesn’t match the efficiency metrics specified by the venture. Iteration by way of these refinements can occur a number of instances, and every tweak within the mannequin can carry with it elevated understanding and higher efficiency. Refinement and evaluating the mannequin on this manner is the important thing to optimizing its efficiency at assembly the requirements set.
This degree of planning not solely cuts down on the complicated course of of choosing the suitable algorithm, however will even improve the probability {that a} sturdy, well-placed machine studying mannequin could be delivered to bear.
The Outcome: Frequent Machine Studying Algorithms
This part provides an outline of some generally used algorithms for classification, regression, and clustering duties. Figuring out these algorithms, and when to make use of them as guided, can assist people make choices related to their tasks.
Frequent Classification Algorithms
- Logistic Regression: Greatest used for binary classification duties, logistic regression is a an efficient however easy algorithm when the connection between dependent and unbiased variables is linear
- Choice Timber: Appropriate for multi-class and binary classification, determination tree fashions are easy to grasp and use, are helpful in circumstances the place transparency is essential, and might work on each categorical and numerical knowledge
- Assist Vector Machine (SVM): Nice for classifying complicated issues with a transparent boundary between courses in high-dimensional areas
- Naive Bayes: Primarily based upon Bayes’ Theorem, works effectively with giant knowledge units and is usually quick relative to extra complicated fashions, particularly when knowledge is unbiased
Frequent Regression Algorithms
- Linear Regression: Probably the most fundamental regression mannequin in use, handiest when coping with knowledge that may be linearly separated with minimal multicollinearity
- Ridge Regression: Provides regularization to linear regression, designed to scale back complexity and forestall overfitting when coping with extremely correlated knowledge
- Lasso Regression: Like Ridge, additionally consists of regularization, however enforces mannequin simplicity by zeroing out the coefficients of much less influential variables
Frequent Clustering Algorithms
- k-means Clustering: When the variety of clusters and their clear, non-hierarchical separation are obvious, use this straightforward clustering algorithm
- Hierarchical Clustering: Let Hierarchical Clustering facilitate the method of discovering and accessing deeper clusters alongside the way in which, in case your mannequin requires hierarchy
- DBSCAN: Take into account implementing DBSCAN alongside your dataset if the aim is to seek out variable-shaped clusters, flag off seen and far-from clusters in your dataset, or work with extremely noisy knowledge as a normal rule
Maintaining efficiency targets in thoughts, your selection of algorithm could be suited to the traits and targets of your dataset as outlined:
- In conditions the place the info are on the smaller aspect and the geography of courses are effectively understood such that they might simply be distinguished, the implementation of easy fashions — akin to Logistic Regression for classification and Linear Regression for regression — is a good suggestion
- To function on giant datasets or forestall overfitting in modeling your knowledge, you may wish to take into account specializing in extra sophisticated fashions akin to Ridge and Lasso regression for regression issues, and SVM for classification duties
- For clustering functions, if you’re confronted with quite a lot of issues akin to recovering fundamental mouse-click clusters, figuring out extra intricate top-down or bottom-up hierarchies, or working with particularly noisy knowledge, k-means, Hierarchical Clustering, and DBSCAN must be appeared into for these concerns as effectively, depending on the dataset particulars
Abstract
The number of a machine studying algorithm is integral to the success of any knowledge science venture, and an artwork itself. The logical development of many steps on this algorithm choice course of are mentioned all through this text, concluding with a ultimate integration and the doable furthering of the mannequin. Each step is simply as essential because the earlier, as every step has an affect on the mannequin that it guides. One useful resource developed on this article is a straightforward move chart to assist information the selection. The concept is to make use of this as a template for figuring out fashions, not less than on the outset. This may function a basis to construct upon sooner or later, and supply a roadmap to future makes an attempt at constructing machine studying fashions.
This fundamental level holds true: the extra that you simply be taught and discover completely different strategies, the higher you’ll turn into at utilizing these strategies to unravel issues and mannequin knowledge. This requires you to proceed questioning the internals of the algorithms themselves, in addition to to remain open and receptive to new tendencies and even algorithms within the discipline. To be able to be an ideal knowledge scientist, that you must continue learning and stay versatile.
Keep in mind that it may be a enjoyable and rewarding expertise to get your fingers soiled with quite a lot of algorithms and take a look at them out. By following the rules launched on this dialogue you possibly can come to understand the facets of machine studying and knowledge evaluation which might be coated right here, and be ready to deal with points that current themselves sooner or later. Machine studying and knowledge science will undoubtedly current quite a few challenges, however in some unspecified time in the future these challenges turn into expertise factors that may assist propel you to success.
Matthew Mayo (@mattmayo13) holds a Grasp’s diploma in laptop science and a graduate diploma in knowledge mining. As Managing Editor, Matthew goals to make complicated knowledge science ideas accessible. His skilled pursuits embody pure language processing, machine studying algorithms, and exploring rising AI. He’s pushed by a mission to democratize data within the knowledge science group. Matthew has been coding since he was 6 years outdated.
 Structure")

