






The Reporting API is an rising net customary that gives a generic reporting mechanism for points occurring on the browsers visiting your manufacturing web site. The experiences you obtain element points corresponding to safety violations or soon-to-be-deprecated APIs, from customers’ browsers from everywhere in the world.
Amassing experiences is commonly so simple as specifying an endpoint URL within the HTTP header; the browser will mechanically begin forwarding experiences protecting the problems you have an interest in to these endpoints. Nevertheless, processing and analyzing these experiences is just not that straightforward. For instance, you might obtain a large variety of experiences in your endpoint, and it’s doable that not all of them shall be useful in figuring out the underlying downside. In such circumstances, distilling and fixing points could be fairly a problem.
On this weblog publish, we’ll share how the Google safety workforce makes use of the Reporting API to detect potential points and determine the precise issues inflicting them. We’ll additionally introduce an open supply answer, so you possibly can simply replicate Google’s strategy to processing experiences and appearing on them.
Some errors solely happen in manufacturing, on customers’ browsers to which you haven’t any entry. You will not see these errors regionally or throughout improvement as a result of there could possibly be sudden situations actual customers, actual networks, and actual units are in. With the Reporting API, you instantly leverage the browser to observe these errors: the browser catches these errors for you, generates an error report, and sends this report back to an endpoint you have specified.
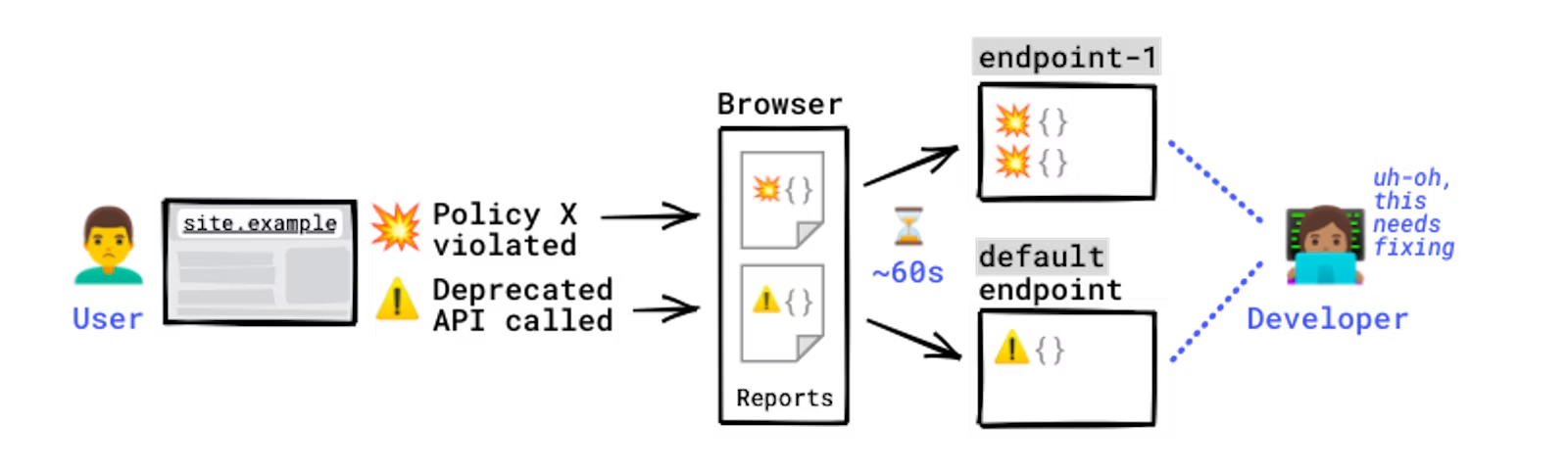
How experiences are generated and despatched.
Errors you possibly can monitor with the Reporting API embrace:
For a full record of error sorts you possibly can monitor, see use cases and report types.
The Reporting API is activated and configured utilizing HTTP response headers: it is advisable to declare the endpoint(s) you need the browser to ship experiences to, and which error sorts you need to monitor. The browser then sends experiences to your endpoint in POST requests whose payload is an inventory of experiences.
Instance setup:
# Instance setup to obtain CSP violations experiences, Doc-Coverage violations experiences, and Deprecation experiences
Reporting-Endpoints: main-endpoint=”https://experiences.instance/major”, default=”https://reports.example/default“
# CSP violations and Doc-Coverage violations will be despatched to `main-endpoint`
Content material-Safety-Coverage: script-src ‘self’; object-src ‘none’; report-to main-endpoint;
Doc-Coverage: document-write=?0; report-to=main-endpoint;
# Deprecation experiences are generated mechanically and do not want an specific endpoint; they’re at all times despatched to the `default` endpoint
Observe: Some insurance policies help “report-only” mode. This implies the coverage sends a report, however does not truly implement the restriction. This may also help you gauge if the coverage is working successfully.
Chrome customers whose browsers generate experiences can see them in DevTools in the Application panel:

Instance of viewing experiences within the Software panel of DevTools.
You’ll be able to generate numerous violations and see how they’re acquired on a server in the reporting endpoint demo:

Instance violation experiences
The Reporting API is supported by Chrome, and partially by Safari as of March 2024. For particulars, see the browser support desk.
Google advantages from with the ability to uplift safety at scale. Net platform mitigations like Content Security Policy, Trusted Types, Fetch Metadata, and the Cross-Origin Opener Policy assist us engineer away complete courses of vulnerabilities throughout tons of of Google merchandise and 1000’s of particular person companies, as described in this blogpost.
One of many engineering challenges of deploying safety insurance policies at scale is figuring out code areas which might be incompatible with new restrictions and that will break if these restrictions had been enforced. There’s a widespread 4-step course of to resolve this downside:
- Roll out insurance policies in report-only mode (CSP report-only mode example). This instructs browsers to execute client-side code as standard, however collect data on any occasions the place the coverage could be violated if it had been enforced. This data is packaged in violation experiences which might be despatched to a reporting endpoint.
- The violation experiences have to be triaged to hyperlink them to areas in code which might be incompatible with the coverage. For instance, some code bases could also be incompatible with safety insurance policies as a result of they use a harmful API or use patterns that blend consumer information and code.
- The recognized code areas are refactored to make them suitable, for instance by utilizing protected variations of harmful APIs or altering the way in which consumer enter is combined with code. These refactorings uplift the safety posture of the code base by serving to cut back the utilization of harmful coding patterns.
- When all code areas have been recognized and refactored, the coverage could be faraway from report-only mode and absolutely enforced. Observe that in a typical roll out, we iterate steps 1 via 3 to make sure that we now have triaged all violation experiences.
With the Reporting API, we now have the power to run this cycle utilizing a unified reporting endpoint and a single schema for a number of safety features. This permits us to assemble experiences for a wide range of options throughout completely different browsers, code paths, and varieties of customers in a centralized approach.
Observe: A violation report is generated when an entity is trying an motion that one among your insurance policies forbids. For instance, you have set CSP on one among your pages, however the web page is making an attempt to load a script that is not allowed by your CSP. Most experiences generated through the Reporting API are violation experiences, however not all — different sorts embrace deprecation experiences and crash experiences. For particulars, see Use cases and report types.
Sadly, it’s common for noise to creep into streams of violation experiences, which may make discovering incompatible code areas troublesome. For instance, many browser extensions, malware, antivirus software program, and devtools customers inject third-party code into the DOM or use forbidden APIs. If the injected code is incompatible with the coverage, this will result in violation experiences that can’t be linked to our code base and are subsequently not actionable. This makes triaging experiences troublesome and makes it arduous to be assured that each one code areas have been addressed earlier than implementing new insurance policies.
Over time, Google has developed quite a lot of methods to gather, digest, and summarize violation experiences into root causes. Here’s a abstract of probably the most helpful methods we consider builders can use to filter out noise in reported violations:
Concentrate on root causes
It’s usually the case {that a} piece of code that’s incompatible with the coverage executes a number of occasions all through the lifetime of a browser tab. Every time this occurs, a brand new violation report is created and queued to be despatched to the reporting endpoint. This will shortly result in a big quantity of particular person experiences, a lot of which include redundant data. Due to this, grouping violation experiences into clusters permits builders to summary away particular person violations and assume when it comes to root causes. Root causes are easier to grasp and may velocity up the method of figuring out helpful refactorings.
Let’s check out an instance to grasp how violations could also be grouped. As an illustration, a report-only CSP that forbids using inline JavaScript occasion handlers is deployed. Violation experiences are created on each occasion of these handlers and have the next fields set:
- The
blockedURLarea is ready toinline, which describes the kind of violation. - The
scriptSamplearea is ready to the primary few bytes of the contents of the occasion handler within the area. - The
documentURLarea is ready to the URL of the present browser tab.
More often than not, these three fields uniquely determine the inline handlers in a given URL, even when the values of different fields differ. That is widespread when there are tokens, timestamps, or different random values throughout web page hundreds. Relying in your utility or framework, the values of those fields can differ in refined methods, so with the ability to do fuzzy matches on reporting values can go a great distance in grouping violations into actionable clusters. In some circumstances, we are able to group violations whose URL fields have identified prefixes, for instance all violations with URLs that begin with chrome-extension, moz-extension, or safari-extension could be grouped collectively to set root causes in browser extensions except for these in our codebase with a excessive diploma of confidence.
Growing your personal grouping methods helps you keep centered on root causes and may considerably cut back the variety of violation experiences it is advisable to triage. Typically, it ought to at all times be doable to pick out fields that uniquely determine fascinating varieties of violations and use these fields to prioritize an important root causes.
Leverage ambient data
One other approach of distinguishing non-actionable from actionable violation experiences is ambient data. That is information that’s contained in requests to our reporting endpoint, however that isn’t included within the violation experiences themselves. Ambient data can trace at sources of noise in a shopper’s arrange that may assist with triage:
- Consumer Agent or User Agent client hints: Consumer brokers are an amazing tell-tale signal of non-actionable violations. For instance, crawlers, bots, and a few cellular purposes use customized consumer brokers whose habits differs from well-supported browser engines and that may set off distinctive violations. In different circumstances, some violations might solely set off in a selected browser or be attributable to modifications in nightly builds or newer variations of browsers. With out consumer agent data, these violations could be considerably tougher to research.
- Trusted customers: Browsers will connect any obtainable cookies to requests made to a reporting endpoint by the Reporting API, if the endpoint is same-site with the doc the place the violation happens. Capturing cookies is beneficial for figuring out the kind of consumer that prompted a violation. Usually, probably the most actionable violations come from trusted customers that aren’t prone to have invasive extensions or malware, like firm workers or web site directors. In case you are not capable of seize authentication data via your reporting endpoint, take into account rolling out report-only insurance policies to trusted customers first. Doing so means that you can construct a baseline of actionable violations earlier than rolling out your insurance policies to most people.
- Variety of distinctive customers: As a normal precept, customers of typical options or code paths ought to generate roughly the identical violations. This permits us to flag violations seen by a small variety of customers as doubtlessly suspicious, since they counsel {that a} consumer’s specific setup is likely to be at fault, quite than our utility code. A technique of ‘counting customers’ is to maintain notice of the variety of distinctive IP addresses that reported a violation. Approximate counting algorithms are easy to make use of and may also help collect this data with out monitoring particular IP addresses. For instance, the HyperLogLog algorithm requires only a few bytes to approximate the variety of distinctive parts in a set with a excessive diploma of confidence.
Map violations to supply code (superior)
Some varieties of violations have a source_file area or equal. This area represents the JavaScript file that triggered the violation and is normally accompanied by a line and column quantity. These three bits of information are a high-quality sign that may level on to strains of code that should be refactored.
Nonetheless, it’s usually the case that supply information fetched by browsers are compiled or minimized and do not map on to your code base. On this case, we suggest you utilize JavaScript supply maps to map line and column numbers between deployed and authored files. This lets you translate instantly from violation experiences to strains of supply code, yielding extremely actionable report teams and root causes.
The Reporting API sends browser-side occasions, corresponding to safety violations, deprecated API calls, and browser interventions, to the desired endpoint on a per-event foundation. Nevertheless, as defined within the earlier part, to distill the actual points out of these experiences, you want an information processing system in your finish.
Thankfully, there are many choices within the business to arrange the required structure, together with open supply merchandise. The elemental items of the required system are the next:
- API endpoint: An online server that accepts HTTP requests and handles experiences in a JSON format
- Storage: A storage server that shops acquired experiences and experiences processed by the pipeline
- Information pipeline: A pipeline that filters out noise and extracts and aggregates required metadata into constellations
- Information visualizer: A software that gives insights on the processed experiences
Options for every of the elements listed above are made obtainable by public cloud platforms, SaaS companies, and as open supply software program. See the Alternative solutions part for particulars, and the next part outlining a pattern utility.
Pattern utility: Reporting API Processor
That can assist you perceive methods to obtain experiences from browsers and methods to deal with these acquired experiences, we created a small sample application that demonstrates the next processes which might be required for distilling net utility safety points from experiences despatched by browsers:
- Report ingestion to the storage
- Noise discount and information aggregation
- Processed report information visualization
Though this pattern is counting on Google Cloud, you possibly can change every of the elements together with your most popular applied sciences. An outline of the pattern utility is illustrated within the following diagram:

Elements described as inexperienced packing containers are elements that it is advisable to implement by your self. Forwarder is an easy net server that receives experiences within the JSON format and converts them to the schema for Bigtable. Beam-collector is an easy Apache Beam pipeline that filters noisy experiences, aggregates related experiences into the form of constellations, and saves them as CSV information. These two elements are the important thing components to make higher use of experiences from the Reporting API.
Attempt it your self
As a result of this can be a runnable pattern utility, you’ll be able to deploy all elements to a Google Cloud venture and see the way it works by your self. The detailed conditions and the directions to arrange the pattern system are documented within the README.md file.
Apart from the open supply answer we shared, there are a variety of instruments obtainable to help in your utilization of the Reporting API. A few of them embrace:
- Report-collecting companies like report-uri and uriports.
- Software error monitoring platforms like Sentry, Datadog, and so on.
Apart from pricing, take into account the next factors when choosing options:
- Are you comfy sharing any of your utility’s URLs with a third-party report collector? Even when the browser strips delicate data from these URLs, delicate data may get leaked this way. If this sounds too dangerous on your utility, function your personal reporting endpoint.
- Does this collector help all report sorts you want? For instance, not all reporting endpoint options help COOP/COEP violation experiences.
On this article, we defined how net builders can gather client-side points by utilizing the Reporting API, and the challenges of distilling the actual issues out of the collected experiences. We additionally launched how Google solves these challenges by filtering and processing experiences, and shared an open supply venture that you need to use to copy the same answer. We hope this data will inspire extra builders to make the most of the Reporting API and, in consequence, make their web site safer and sustainable.


