







(CoreDESIGN/Shutterstock)
Apache Pinot grew well-liked amongst corporations like Uber for its functionality to serve SQL queries to 1000’s of exterior customers with sub-second latency. Now the business open-source vendor backing Pinot, StarTree, introduced that it’s increasing the database into its first inside use case, analyzing observability information. StarTree additionally introduced launch of an automatic anomaly detection utility referred to as ThirdEye, and unveiled the addition of vector help within the open supply challenge.
Apache Pinot is a distributed columnar database that was developed at LinkedIn in 2015 to serve the social media firm’s huge urge for food for real-time queries on information flowing via Apache Kafka, which it additionally created. The open-source product makes use of quite a lot of indexing methods to allow it to course of massive quantities SQL queries towards petabytes of information with out doing full desk scans, that are time-consuming and costly.
“The entire precept of Pinot is to do the least work attainable,” says Chinmay Soman, head of product at StarTree, which relies in San Jose, California. “Many programs are likely to scan plenty of information after which attempt to determine find out how to scan sooner or find out how to course of all that information sooner proper. We don’t do this. Our philosophy is don’t scan in any respect for the queries that it’s worthwhile to run.”
Prospects up thus far have used Pinot to unravel a few of their hardest massive information challenges for exterior customers. As an illustration, LinkedIn makes use of Pinot to serve canned queries, comparable to what number of customers have seen your profile and what number of impressions has your submit garnered. Uber has a number of use instances for Pinot, together with utilizing Pinot to power dashboards for its UberEats operation.
Exterior use instances are the toughest downside to unravel as a result of they entail serving information to thousands and thousands of customers with a sub-second question latencies, Soman says. “And the rewards are larger,” he says. “It grows your retention. The general development of the corporate depends upon this.”
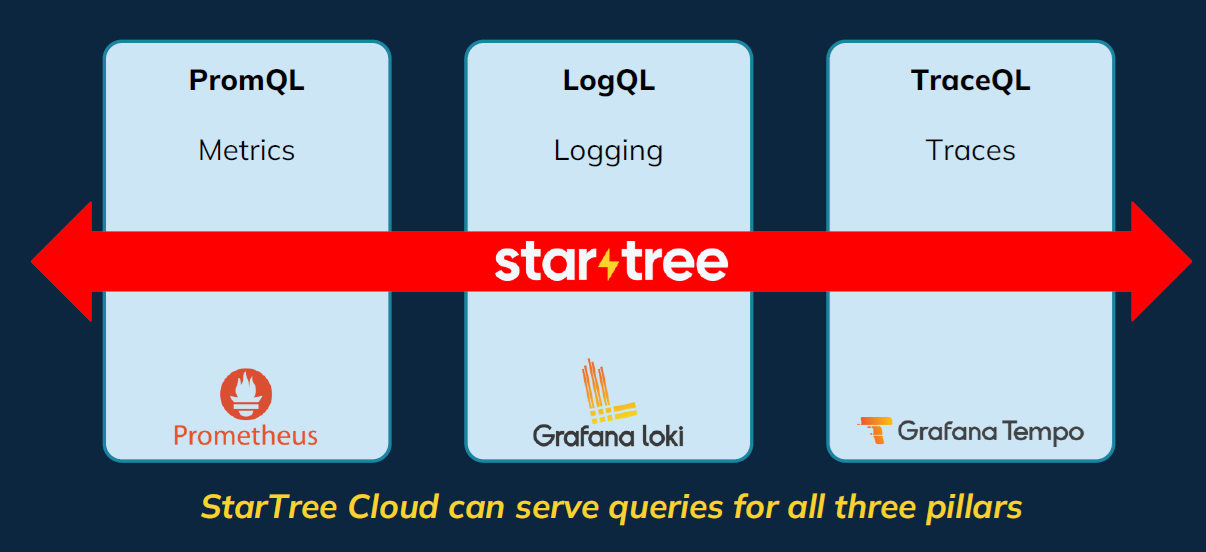
StarTree Cloud Observability covers the three forms of observability information: Logs, metrics, and traces (Picture courtesy StarTree)
On the urging of consumers like Uber, which not too long ago changed a 1,000-node Elastic cluster with a 75-node Pinot system, StarTree is increasing its business Pinot providing, referred to as StarTree Cloud, into inside real-time analytics use instances. The primary inside use case is analyzing observability information, together with logs, metrics, and traces.
StarTree Cloud Observability will carry a number of benefits over incumbent observability stacks, in accordance with Soman. As an illustration, the Pinot-based providing can be open, enabling customers to select and select what different elements they need to use, comparable to BI instruments and assortment brokers.
The brand new cloud providing will help OpenTelemetry, the rising open normal for logs, metrics, and traces, in addition to Prometheus for metrics, Grafana Loki for logs, and Grafana Tempo for traces. StarTree Cloud Observability additionally received’t carry any lock-in for observability information the best way some distributors have constructed their options to do, Soman says.
“StarTree will develop into the storage and question layer within the stack after which corporations are free to decide on different their very own elements for the opposite remainder of the stack,” he says. “The differentiator right here is the core engine. StarTree is a distributed database which is straightforward to scale out. It’s tremendous quick utilizing all the assorted indexing applied sciences that now we have. And it’s value environment friendly, so now we have a method to retailer historic information in deep cloud storage whereas nonetheless sustaining sub-second latencies.”
Uber and Cisco, one other Pinot buyer, have already adopted Pinot for observability use instances, and now common StarTree Cloud clients can do observability too, says Peter Corless, StarTree director of product advertising. “We’re principally providing this as a service so that folks don’t have to have the ability to be Cisco-sized to have the ability to do that,” he says.
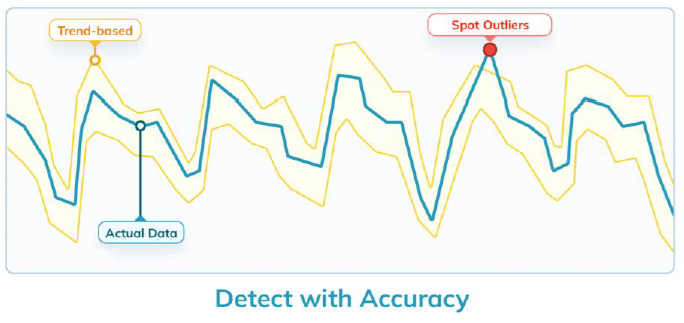
ThirdEye mechanically detects anomalies and root-cause evaluation (Picture courtesy StarTree)
StarTree additionally introduced the overall availability of ThirdEye, an automatic anomaly detection and root trigger evaluation device designed particularly for enterprise metrics.
ThirdEye leverages StarTree’s functionality to partition time-series information and carry out mixture features on that information, comparable to rollups. The software program then makes use of machine studying methods to detect patterns within the information that may in all probability escape the eyes of human analysts.
“Conventional options don’t work. They’re not able to studying the historic sample of information,” Soman says. “ThirdEye is ready to study that, to do a week-over-week or month-or-month evaluation after which detect correct outliers in your time-series information.”
As soon as ThirdEye detects an anomaly, it additionally performs an automatic root-cause evaluation that includes analyzing lots of of dimensions related to the metric to find out the possible reason behind the anomaly.
“For instance, for LinkedIn web page views, dimensions could possibly be geolocation or a sort of system, Android or iOS. Or it could possibly be a selected model of the software program that’s operating,” Soman says. “It’ll undergo all of these and see which dimension triggered this metric to go up or down.”![]()
StarTree additionally introduced the personal preview of StarTree Cloud Write API, a brand new “push” information integration system that may allow customers to attach their Pinot cluster on to ETL information pipelines managed by programs like Debezium, Fivetran, or dbt.
Whereas Pinot was initially to work with an Apache Kafka message bus to “pull” information into the database, some clients didn’t need to trouble and expense of operating a Kafka cluster, and so now they produce other choices, in accordance with Soman.
StarTree can be launching a “free perpetually tier” for its StarTree Cloud, which provides clients a vast storage possibility for his or her cloud model of Pinot. Whereas some clients are storing a number of petabytes of information in Pinot, that’s in all probability not possibility for the free perpetually tier, which does carry some utilization restrictions.
Lastly, StarTree introduced that it’s including vector storage and vector search capabilities to the open supply Apache Pinot challenge. This may enable builders retailer vector embeddings in Pinot cluster after which be capable of do similarity search queries instantly inside Pinot, Soman says.
“So basically we’re inserting ourselves as a scalable vector DB,” he says. “You may construct all types of GenAI functions. This may develop into one of many infrastructure items for constructing these functions.”
StarTree made these bulletins amidst the Actual-Time Analytics Summit, which it’s internet hosting this week in San Jose. You could find extra details about the occasion here.
Associated Objects:
Apache Pinot Uncorks Real-Time Data for Ad-Tech Firm
StarTree Keeps Real-Time Analytics Fresh with New Options for Pinot
StarTree Uncorks $47 Million for Pinot
Apache Pinot, distributed database, Grafana, logs, metrics, observability, OpenTelemetery, Prometheus, real-time analytics, Real-Time Analytics Summit, ThirdEye, traces


