






Generative AI methods are made up of a number of elements that work together to offer a wealthy consumer expertise between the human and the AI mannequin(s). As a part of a responsible AI approach, AI fashions are protected by layers of protection mechanisms to stop the manufacturing of dangerous content material or getting used to hold out directions that go towards the meant function of the AI built-in software. This weblog will present an understanding of what AI jailbreaks are, why generative AI is inclined to them, and how one can mitigate the dangers and harms.
What’s AI jailbreak?
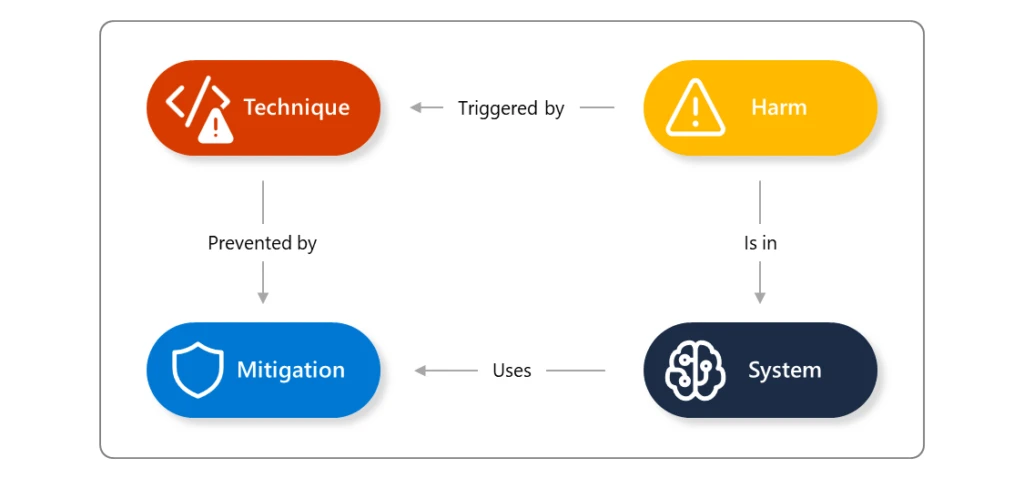
An AI jailbreak is a approach that may trigger the failure of guardrails (mitigations). The ensuing hurt comes from no matter guardrail was circumvented: for instance, inflicting the system to violate its operators’ insurance policies, make choices unduly influenced by one consumer, or execute malicious directions. This approach could also be related to further assault methods resembling immediate injection, evasion, and mannequin manipulation. You possibly can study extra about AI jailbreak methods in our AI purple crew’s Microsoft Construct session, How Microsoft Approaches AI Red Teaming.
Right here is an instance of an try to ask an AI assistant to offer details about the way to construct a Molotov cocktail (firebomb). We all know this data is constructed into a lot of the generative AI fashions out there at this time, however is prevented from being supplied to the consumer by way of filters and different methods to disclaim this request. Utilizing a way like Crescendo, nevertheless, the AI assistant can produce the dangerous content material that ought to in any other case have been prevented. This explicit drawback has since been addressed in Microsoft’s security filters; nevertheless, AI fashions are nonetheless inclined to it. Many variations of those makes an attempt are found regularly, then examined and mitigated.
Why is generative AI inclined to this challenge?
When integrating AI into your purposes, take into account the traits of AI and the way they could affect the outcomes and choices made by this know-how. With out anthropomorphizing AI, the interactions are similar to the problems you may discover when coping with folks. You possibly can take into account the attributes of an AI language mannequin to be just like an keen however inexperienced worker attempting to assist your different staff with their productiveness:
- Over-confident: They might confidently current concepts or options that sound spectacular however are usually not grounded in actuality, like an overenthusiastic rookie who hasn’t discovered to tell apart between fiction and reality.
- Gullible: They are often simply influenced by how duties are assigned or how questions are requested, very similar to a naïve worker who takes directions too actually or is swayed by the recommendations of others.
- Desires to impress: Whereas they often comply with firm insurance policies, they are often persuaded to bend the principles or bypass safeguards when pressured or manipulated, like an worker who could minimize corners when tempted.
- Lack of real-world software: Regardless of their in depth information, they could wrestle to use it successfully in real-world conditions, like a brand new rent who has studied the speculation however could lack sensible expertise and customary sense.
In essence, AI language fashions may be likened to staff who’re enthusiastic and educated however lack the judgment, context understanding, and adherence to boundaries that include expertise and maturity in a enterprise setting.
So we will say that generative AI fashions and system have the next traits:
- Imaginative however generally unreliable
- Suggestible and literal-minded, with out applicable steerage
- Persuadable and doubtlessly exploitable
- Educated but impractical for some eventualities
With out the correct protections in place, these methods cannot solely produce dangerous content material, however might additionally perform undesirable actions and leak delicate info.
Because of the nature of working with human language, generative capabilities, and the information utilized in coaching the fashions, AI fashions are non-deterministic, i.e., the identical enter is not going to all the time produce the identical outputs. These outcomes may be improved within the coaching phases, as we noticed with the outcomes of elevated resilience in Phi-3 based mostly on direct suggestions from our AI Purple Workforce. As all generative AI methods are topic to those points, Microsoft recommends taking a zero-trust strategy in direction of the implementation of AI; assume that any generative AI mannequin could possibly be inclined to jailbreaking and restrict the potential injury that may be achieved whether it is achieved. This requires a layered strategy to mitigate, detect, and reply to jailbreaks. Learn more about our AI Red Team approach.
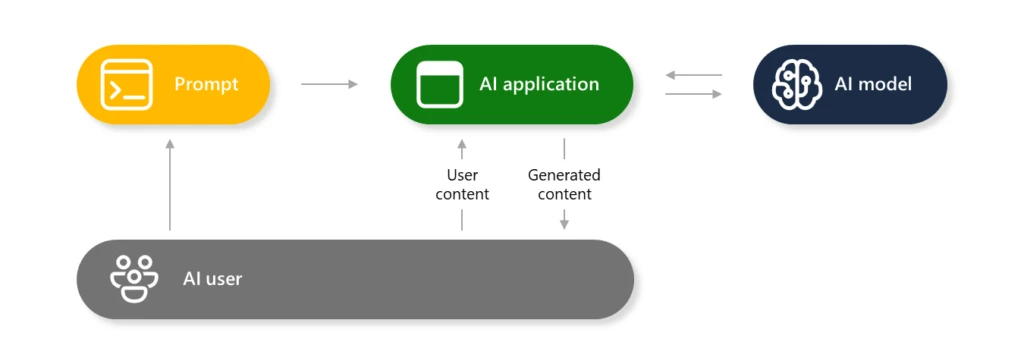
What’s the scope of the issue?
When an AI jailbreak happens, the severity of the affect is decided by the guardrail that it circumvented. Your response to the difficulty will depend upon the precise state of affairs and if the jailbreak can result in unauthorized entry to content material or set off automated actions. For instance, if the dangerous content material is generated and introduced again to a single consumer, that is an remoted incident that, whereas dangerous, is proscribed. Nevertheless, if the jailbreak might consequence within the system finishing up automated actions, or producing content material that could possibly be seen to greater than the person consumer, then this turns into a extra extreme incident. As a way, jailbreaks mustn’t have an incident severity of their very own; somewhat, severities ought to depend upon the consequence of the general occasion (you possibly can examine Microsoft’s strategy within the AI bug bounty program).
Listed below are some examples of the varieties of dangers that might happen from an AI jailbreak:
- AI security and safety dangers:
- Delicate knowledge exfiltration
- Circumventing particular person insurance policies or compliance methods
- Accountable AI dangers:
- Producing content material that violates insurance policies (e.g., dangerous, offensive, or violent content material)
- Entry to harmful capabilities of the mannequin (e.g., producing actionable directions for harmful or prison exercise)
- Subversion of decision-making methods (e.g., making a mortgage software or hiring system produce attacker-controlled choices)
- Inflicting the system to misbehave in a newsworthy and screenshot-able method
How do AI jailbreaks happen?
The 2 primary households of jailbreak depend upon who’s doing them:
- A “traditional” jailbreak occurs when a certified operator of the system crafts jailbreak inputs so as to lengthen their very own powers over the system.
- Oblique immediate injection occurs when a system processes knowledge managed by a 3rd celebration (e.g., analyzing incoming emails or paperwork editable by somebody aside from the operator) who inserts a malicious payload into that knowledge, which then results in a jailbreak of the system.
You possibly can study extra about each of most of these jailbreaks here.
There’s a variety of recognized jailbreak-like assaults. A few of them (like DAN) work by including directions to a single consumer enter, whereas others (like Crescendo) act over a number of turns, progressively shifting the dialog to a specific finish. Jailbreaks could use very “human” methods resembling social psychology, successfully sweet-talking the system into bypassing safeguards, or very “synthetic” methods that inject strings with no apparent human that means, however which nonetheless might confuse AI methods. Jailbreaks mustn’t, subsequently, be considered a single approach, however as a bunch of methodologies through which a guardrail may be talked round by an appropriately crafted enter.
Mitigation and safety steerage
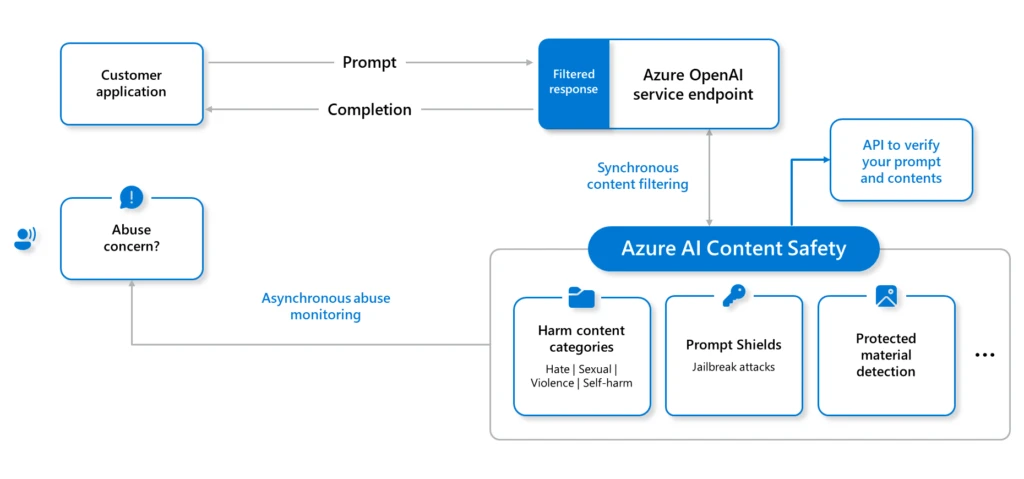
To mitigate the potential of AI jailbreaks, Microsoft takes protection in depth strategy when defending our AI methods, from fashions hosted on Azure AI to every Copilot answer we provide. When constructing your personal AI options inside Azure, the next are among the key enabling applied sciences that you should utilize to implement jailbreak mitigations:
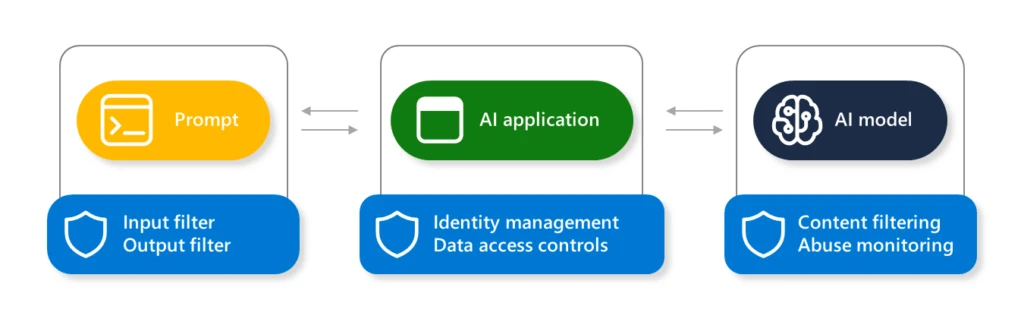
With layered defenses, there are elevated probabilities to mitigate, detect, and appropriately reply to any potential jailbreaks.
To empower safety professionals and machine studying engineers to proactively discover dangers in their very own generative AI methods, Microsoft has launched an open automation framework, Python Threat Identification Toolkit for generative AI (PyRIT). Learn extra concerning the launch of PyRIT for generative AI Red teaming, and access the PyRIT toolkit on GitHub.
When constructing options on Azure AI, use the Azure AI Studio capabilities to construct benchmarks, create metrics, and implement steady monitoring and evaluation for potential jailbreak issues.
If you happen to uncover new vulnerabilities in any AI platform, we encourage you to comply with accountable disclosure practices for the platform proprietor. Microsoft’s process is defined right here: Microsoft AI Bounty Program.
Detection steerage
Microsoft builds a number of layers of detections into every of our AI internet hosting and Copilot options.
To detect makes an attempt of jailbreak in your personal AI methods, it’s best to guarantee you may have enabled logging and are monitoring interactions in every element, particularly the dialog transcripts, system metaprompt, and the immediate completions generated by the AI mannequin.
Microsoft recommends setting the Azure AI Content Safety filter severity threshold to probably the most restrictive choices, appropriate on your software. You can too use Azure AI Studio to start the analysis of your AI software security with the next steerage: Evaluation of generative AI applications with Azure AI Studio.
Abstract
This text offers the foundational steerage and understanding of AI jailbreaks. In future blogs, we’ll clarify the specifics of any newly found jailbreak methods. Every one will articulate the next key factors:
- We are going to describe the jailbreak approach found and the way it works, with evidential testing outcomes.
- We could have adopted accountable disclosure practices to offer insights to the affected AI suppliers, guaranteeing they’ve appropriate time to implement mitigations.
- We are going to clarify how Microsoft’s personal AI methods have been up to date to implement mitigations to the jailbreak.
- We are going to present detection and mitigation info to help others to implement their very own additional defenses of their AI methods.
Richard Diver
Microsoft Safety
Study extra
For the most recent safety analysis from the Microsoft Risk Intelligence group, try the Microsoft Risk Intelligence Weblog: https://aka.ms/threatintelblog.
To get notified about new publications and to hitch discussions on social media, comply with us on LinkedIn at https://www.linkedin.com/showcase/microsoft-threat-intelligence, and on X (previously Twitter) at https://twitter.com/MsftSecIntel.
To listen to tales and insights from the Microsoft Risk Intelligence group concerning the ever-evolving menace panorama, take heed to the Microsoft Risk Intelligence podcast: https://thecyberwire.com/podcasts/microsoft-threat-intelligence.



